The upcoming next release of eXist will introduce quite a few changes with respect to index types and index creation. While your old index configuration should still work with the new version, knowing the new features and possibilities can sometimes result in a dramatic performance boost.
To better understand the changes, we have to look at two different areas of development, which both have direct effects on indexing features:
- The switch to a modularized indexing architecture
- The new query-rewriting optimizer
Modularized Index Architecture
So far, all indexes in eXist were part of the database core, i.e. their creation and configuration was hardcoded, their indexing methods were directly called from the main indexer. Certainly this "design" was too limiting. Most XML projects tend to develop slightly different indexing needs and it is hard to define one type of index that fits them all.
We thus decided to replace the old hard-wired indexes by a completely new architecture, which is based on pluggable indexing pipelines and makes nearly no assumptions about the data to be indexed. In the new design, the database core just passes a stream of index events to a pipeline of external index plugins. The index plugin scans the stream for interesting events and processes them according to its own logic (for example, the spatial plugin listens for GML geometries in the source XML to enable spatial queries). For the DB core, the index is now a black box, which handles its own creation, configuration, destruction etc..
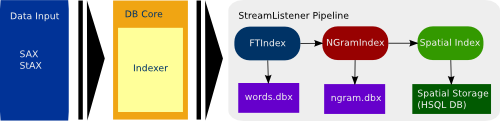
The plugin architecture makes it even possible to use other database systems to index contents stored in eXist. The new spatial index is a good example as it currently uses an SQL database to index spatial data.
Consequently, all the new index modules were moved out of the eXist core packages and into an extra directory extensions/indexes. New indexes can be added any time (copy the directory structure from an existing index and start implementing).
Our work is not finished yet as some of the old indexes have only be moved in part. However, we implemented two new index plugins: an n-gram index and the spatial index already mentioned above. Both plugins served as a proof-of-concept and matured while we were working on the new architecture. We also heard of users who have already written their own customized index implementation.
Query-Rewriting Optimizer
The second major development which affects the indexing system is a new query-optimizer. It analyzes the query at compile time and searches for optimizable subexpressions within the query tree. If it finds an optimizable expressions, the optimizer will modify the query and wrap some special instructions around the optimizable code block.
Note: right now, you have to enable the optimizer in conf.xml:
Understanding the optimization techniques requires some in-depth knowledge of eXist's indexing scheme and query processing approach. This should be covered by a separate article and I will not go into details here. The basic idea is to limit the number of nodes that need to be processed as early as possible. For example, take the following query:
Let's say we have 100,000 inproceedings and 600,000 author nodes in the database, but only 34 of them were actually written by a "Joe Doe". The index lookups for inproceedings and author can be rather expensive (or at least memory consuming), while finding "Joe Doe" in the index is really cheap (a few milliseconds).
Now, the main trick used by the query optimizer is to evaluate the comparison author = "Joe Doe" ahead of the rest of the query. It then computes the ancestor nodes which happen to be inproceedings elements and puts them into relation with the outer query context.
Obviously, the efficiency of this technique depends on how selective the predicate expression is. Also, the range of expressions which can be optimized automatically is currently limited. For example, the optimizer can not yet deal with conditions in "where" clauses. However, it can speed up some types of XPath predicate expressions by factor 10 or more.
Coming back to indexing: the query-rewriting optimizer changes the evaluation sequence of the query expression. The expression author = "Joe Doe" is processed out of sequence, which means that the context of this expression (the inproceedings nodes) is unknown or not exactly known. This is not a real problem since the result of the expression will be re-contextualized later. But it has some consequences for the indexing:
To make an optimization decision, the optimizer needs to know if an index is available for the subexpression and if it can be used out-of-sequence. If the index depends on a certain context, it can't be used in query rewriting (it could still be used for other optimizations though).
Unfortunately, all the old eXist indexes were designed to be context-dependant. For example, you could define an index only on those author nodes being children of inproceedings elements, but not on those being children of book:
This kind of context-dependant index definitions helps to keep the index small, but it makes it hard for the optimizer to properly rewrite the expression tree without missing some nodes. We thus had to introduce an alternative configuration method which is not context-dependant. To keep things simple, we decided to define the index on the QName of the node alone and to ignore the context altogether:
As you see, the only change is that we are now using an attribute qname instead of the path attribute. An index defined in this way can be used with the optimization techniques described above. This is done transparently and you don't need to provide anything else apart from the index.
You are still free to prefer the path attribute instead of qname (at least for the old indexes, not for the new n-gram index). An index configured like that will be used where possible, but not by the query-rewriting optimizer. The expected performance gain will thus be much smaller.
The main disadvantage of index definitions by qname is that the index might grow much larger (as so often, there's a trade-off between performance and storage space). You cannot index only some author nodes and exclude others in the same collection. On the other hand, the performance win can be dramatic enough to justify an increase in index size. And since eXist allows you to configure different indexes for different database collections, you can always move documents you don't want to be indexed into another collection.
Putting It All Together
Below is an example collection.xconf document, which uses most configuration options. To find out how to create and where to store this document, please refer to the documentation.
Let's walk through this step by step:
We first need to tell the indexer not to create any full text indexes by default (default="none"), not even for attributes (attributes="false"). We then create a standard full text index on all author elements, identified by their QName. The next line declares an index on title, but with the added option content="mixed". This parameter causes the indexer to watch out for mixed-content nodes. For example, if your source XML contains markup like:
You may want to treat "uneven" as a single word so you can query for p |= "uneven". In this case, you need to pass content="mixed" to the indexer. On the other hand, if you have
you probably want to be able to query for "March" even though there's no space between the year and month elements. In this case the standard settings are ok as they will add a virtual break between the elements.
Finally, the index on booktitle is specified in a context-dependant way using the path attribute (which doesn't make that much sense here since only books can have a booktitle).
Range indexes support the XQuery comparison operators (=, less than, greater than …) as well as the standard string functions , , or Range index are type-specific: an index defined on will not be used for string comparisons and vice versa. Also, string indexes will always be case sensitive and can only be used with the default collation. In other words: it is not possible to define a string index for a predefined collation (this is a limitation we plan to address soon).
Finally, let's have a look at n-gram indexes:
The n-gram index splits the text it receives into sequences of n-characters (where n = 3 by default). For example, the text "love me" will be split into the tri-grams: "lov", "ove", "ve_", "e_m", "_me" (I replaced the space char by a _). This type of index is very efficient for exact substring matches, for example:
However, the main benefit of an n-gram index is that it works well with non-european languages like Chinese. The full text index is a bad match for these languages (and terribly slow) as they can not be easily split into whitespace separated tokens (or "words").
Choosing the Right Index
If you are using a version of eXist which already supports the new query optimization techniques (applies to all versions since June 2007), the first rule should be:
Prefer simple index definitions on qname
The optimizer is still work in progress and you may not always see faster query times by following this rule. However, there's rarely a good reason for using a context-dependant index definition, at least in my experience. So to be on the safe side and to benefit from current and future improvements, use qname="author" instead of path="//author".
Use range indexes on strongly typed data or short strings
Range indexes work with the standard XQuery operators and string functions. Querying for something like
will always be slow without an index. As long as no index is defined it, eXist has to scan over every year element in the db, casting its string value to an integer.
For queries on string content, range indexes work well for exact comparisons (author = 'Joe Doe') or regular expressions (matches(author, "^Joe.*")), though you may also consider using a full text index in the latter case. However, please note that range indexes on strings are case-sensitive or rather, to use the correct formulation, sensitive to the default collation.
Consider an n-gram index for exact substring queries on longer text sequences
While range indexes tend to become slow for substring queries (like contains(title, "XSLT 2.0")), an n-gram index is nearly as fast as a full text index, but it also indexes whitespace and punctuation. ngram:contains(title, "XSLT 2.0") will only match titles containing the exact phrase "XSLT 2.0". Please note also that n-gram indexes are case insensitive.
Choose a full text index for tokenizable text where whitespace/punctuation is mostly irrelevant
I don't think I need to explain much here. The full text index is fast and should be used whenever you need to query for any sequence of separate words or tokens in a longer text. It can sometimes even be faster to post-process the returned node set and filter out wrong matches than using a much slower regular expression. The available full text functions and extension operators are described in the documentation.
The full text index is currently undergoing a major redesign, but this should only increase its general usability. For example, it is currently quite difficult to replace the general-purpose tokenizer. This will certainly become much easier in the future.